Excel and PDF purchase orders#
Many B2B buyers keep their own order forms. StackCube lets your team upload those files and extract order lines into the same review queue used by every other channel.
Supported use cases#
- Buyer Excel order forms
- Distributor spreadsheets
- PDF purchase orders
- Scanned order sheets with clear text
- Mixed email body and attachment orders
Setup steps#
- Collect common file examples from major customers.
- Confirm which columns or fields matter for order review.
- Map customer item names to your item catalog.
- Upload test files and review extraction results.
- Add aliases for repeated unmatched lines.
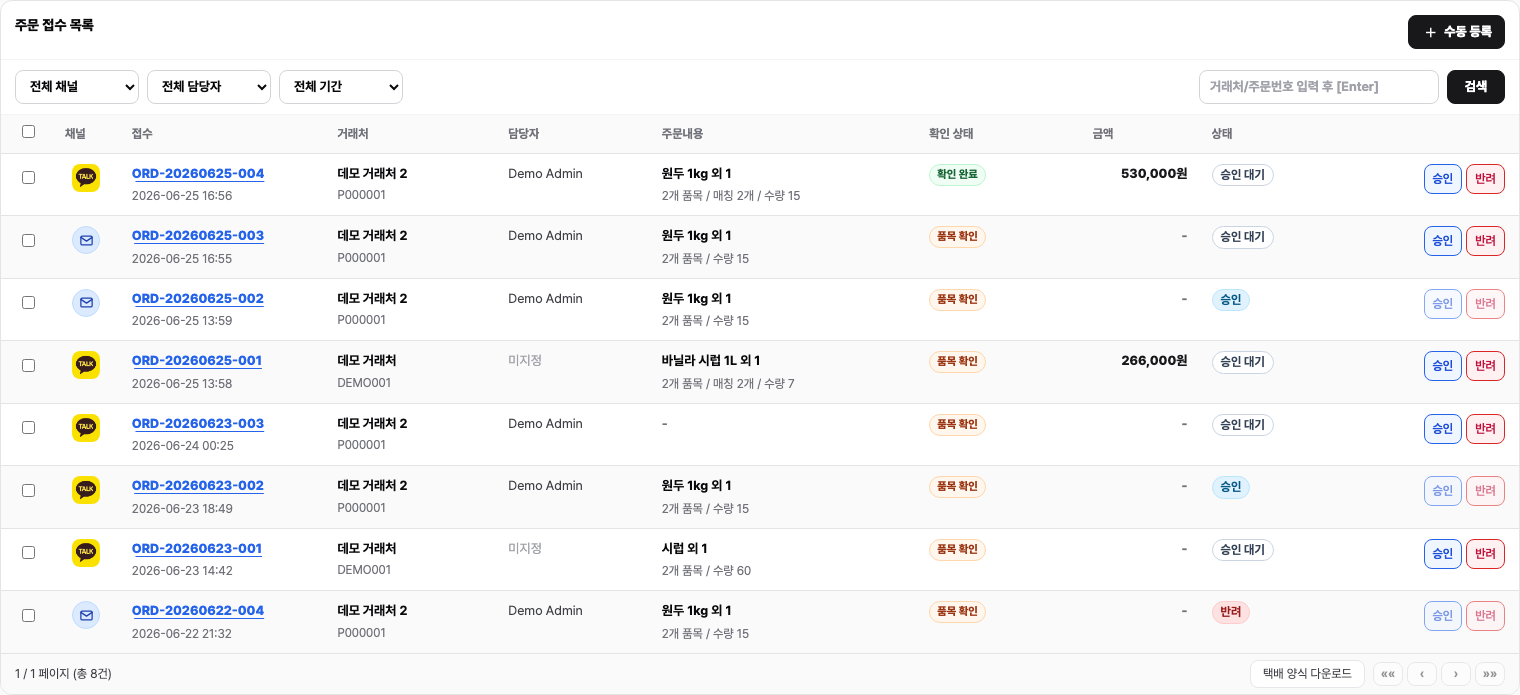
Review focus#
Reviewers should check customer match, item match, quantity, unit, price, delivery date, and notes. File-based orders often include hidden context in headers or comments, so keep the source file available.
When to standardize forms#
Do not force every customer onto a new form immediately. Standardize forms only when a customer repeatedly sends files that create avoidable exceptions.